




在音频编辑领域,从歌曲中提取人声是一项常见的任务,无论是为了制作卡拉OK伴奏、进行音频分析,还是创作混音作品,掌握这一技巧都非常有用。本文将介绍几种常见且有效的方法,帮助大家从歌曲中提取人声。
一、使用在线工具
易我人声分离是一款功能强大的音频编辑工具,它提供了人声分离的功能,您可以在线使用(免下载)这个工具轻松地将音频中的人声与背景音分离开来。具体步骤如下:
步骤1.访问并登录易我人声分离官网页面,选择“人声分离”功能。
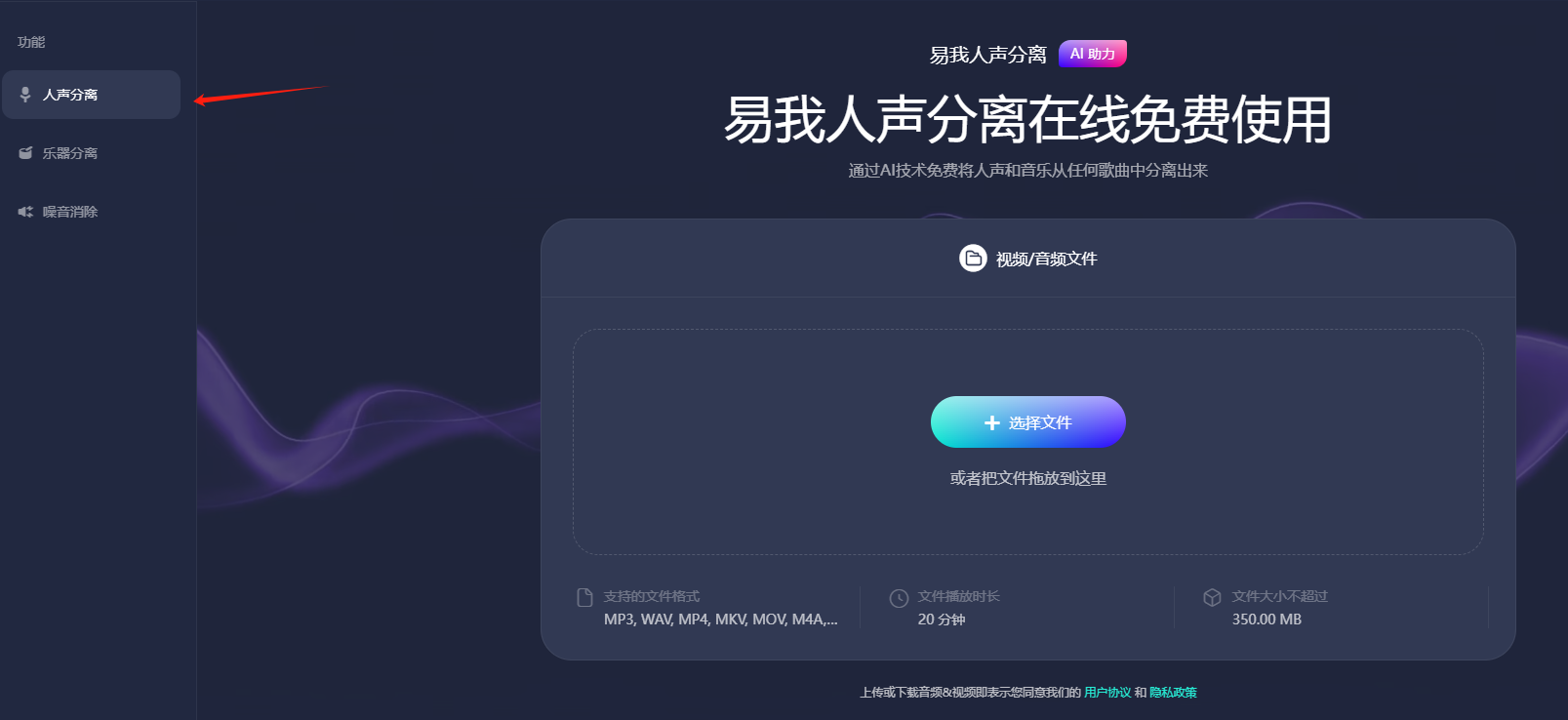
步骤2.点击“选择文件”,把音频或者视频文件上传到网页窗口中(或者直接拖拽文件到窗口中),等待AI处理。


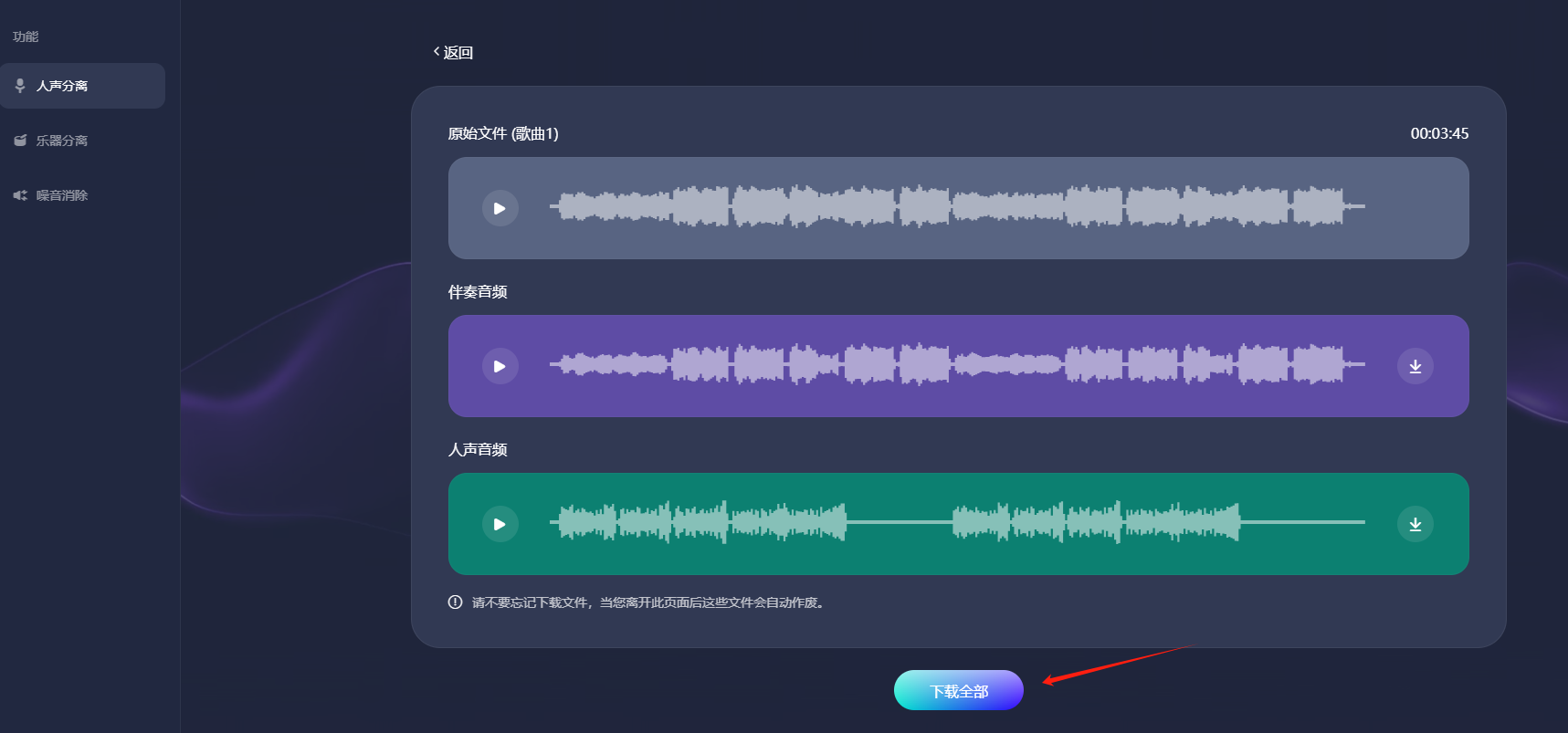
步骤3.AI处理完成后,会生成伴奏音频和人声音频,点击“下载全部”即可把音频下载到您的电脑上。
注意:请不要忘记下载文件,当您离开此页面后这些文件会自动作废。
二、使用音频编辑软件
Audacity是一款免费开源的音频编辑软件,提供了简单但强大的工具来提取音频中的人声。以下是具体步骤:
下载并安装Audacity。
打开Audacity,点击“File”(文件)菜单,选择“Open”(打开)并导入要处理的音频文件。
选择音频文件上的整个轨道,点击“Effect”(效果)菜单,选择“Vocal Reduction and Isolation”(人声减少和隔离)。
在弹出的对话框中,选择“Remove Vocals”(去除人声)或“Isolate Vocals”(隔离人声),根据您的需求进行选择。
调整其他参数如“Slider”(滑块)和“Preview”(预览)选项,直到达到满意的效果。
点击“OK”(确定)应用效果,Audacity将自动处理音频并分离人声。
完成后,点击“File”(文件)菜单,选择“Export”(导出)将提取的纯人声保存为新的音频文件。
三、使用深度学习模型
深度学习模型在音频处理领域也展现出了强大的能力。一些预训练模型,如Spleeter或OpenUnmix,可以有效地分离音频中的人声和伴奏。虽然深度学习模型通常需要进行训练,但使用已训练好的模型可以大大简化这一过程。
总结
以上就是从歌曲中提取人声的一些常见方法。无论是使用在线工具、音频编辑软件还是深度学习模型,都可以根据您的需求和个人偏好选择适合的方法。

 简单好用的人声分离软件,关键还免费
简单好用的人声分离软件,关键还免费

 抒情音乐纯音乐伴奏哪里找?自己如何提取纯音乐伴奏?
抒情音乐纯音乐伴奏哪里找?自己如何提取纯音乐伴奏?
 去背景音乐保留人声的专业指南
去背景音乐保留人声的专业指南
 白燕升演唱豫剧程婴救孤伴奏,纯伴奏制作教程
白燕升演唱豫剧程婴救孤伴奏,纯伴奏制作教程
 歌曲伴奏从哪个软件找?不用找,直接分离伴奏!
歌曲伴奏从哪个软件找?不用找,直接分离伴奏!
 音频编辑的艺术:人声和背景音乐分离
音频编辑的艺术:人声和背景音乐分离
 提取伴奏人声分离软件免费的方法技巧分享
提取伴奏人声分离软件免费的方法技巧分享
 视频怎么提取人声?视频提取人声,不再难!
视频怎么提取人声?视频提取人声,不再难!
 怎么提取背景音乐?独特方法,教你提取背景音乐
怎么提取背景音乐?独特方法,教你提取背景音乐
 音乐怎么去除人声只留背景音乐?去除人声的神奇方法
歌曲去掉人声留伴奏,三个简单技巧奉上
录音怎么去除杂音保留人声?一招提高录音清晰度!
音乐怎么去除人声只留背景音乐?去除人声的神奇方法
歌曲去掉人声留伴奏,三个简单技巧奉上
录音怎么去除杂音保留人声?一招提高录音清晰度!