




音频信号处理,特别是人声和背景音乐的分离,是音频编辑领域中的一项重要技术。如何人声和背景音乐分离出来?随着音频处理技术的不断发展,分离人声和背景音乐的方法日益多样化,既可以通过专业软件实现,也可以借助人工智能技术来完成。
一、基于专业软件的方法
许多音频编辑软件都提供了人声与伴奏分离的功能。这些软件通常具有丰富的音频处理工具和简洁的操作界面,使得用户能够轻松地进行音频编辑和处理。
用户只需打开软件,导入需要处理的音频文件,然后选择人声提取或伴奏提取功能,最后导出分离后的音频文件即可。
二、基于人工智能的方法
深度学习模型可以通过训练大量的音频数据来学习人声和背景音乐的特征,然后根据这些特征来分离它们。这种方法通常具有较高的分离精度和效率。目前已有一些基于深度学习的音频分离工具和服务,如易我人声分离。用户只需上传音频文件,这个工具就会自动将人声轨和乐器轨分开。
如何人声和背景音乐分离出来?以下是易我人声分离具体的分离步骤:
步骤1.访问并登录易我人声分离官网页面,选择“人声分离”功能。
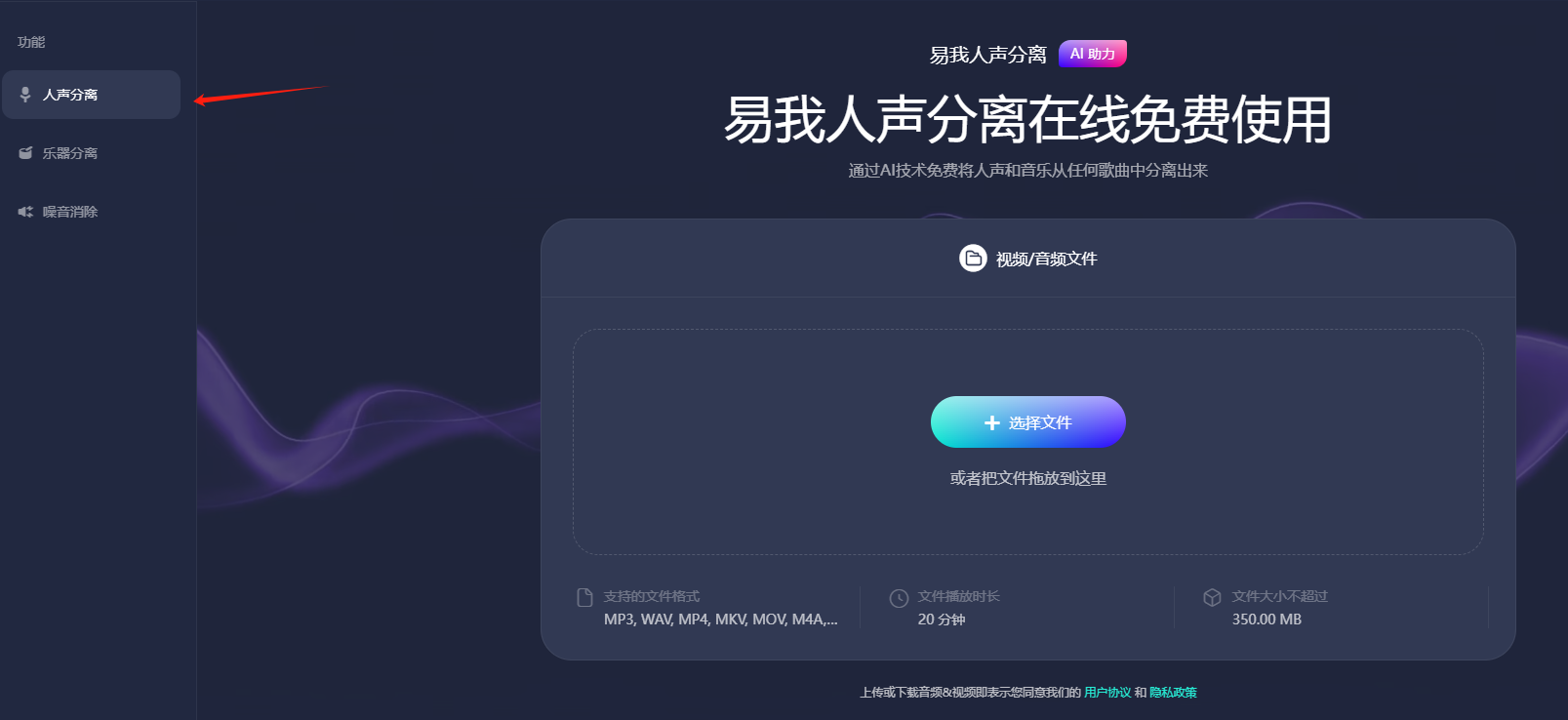
步骤2.点击“选择文件”,把音频或者视频文件上传到网页窗口中(或者直接拖拽文件到窗口中),等待AI处理。


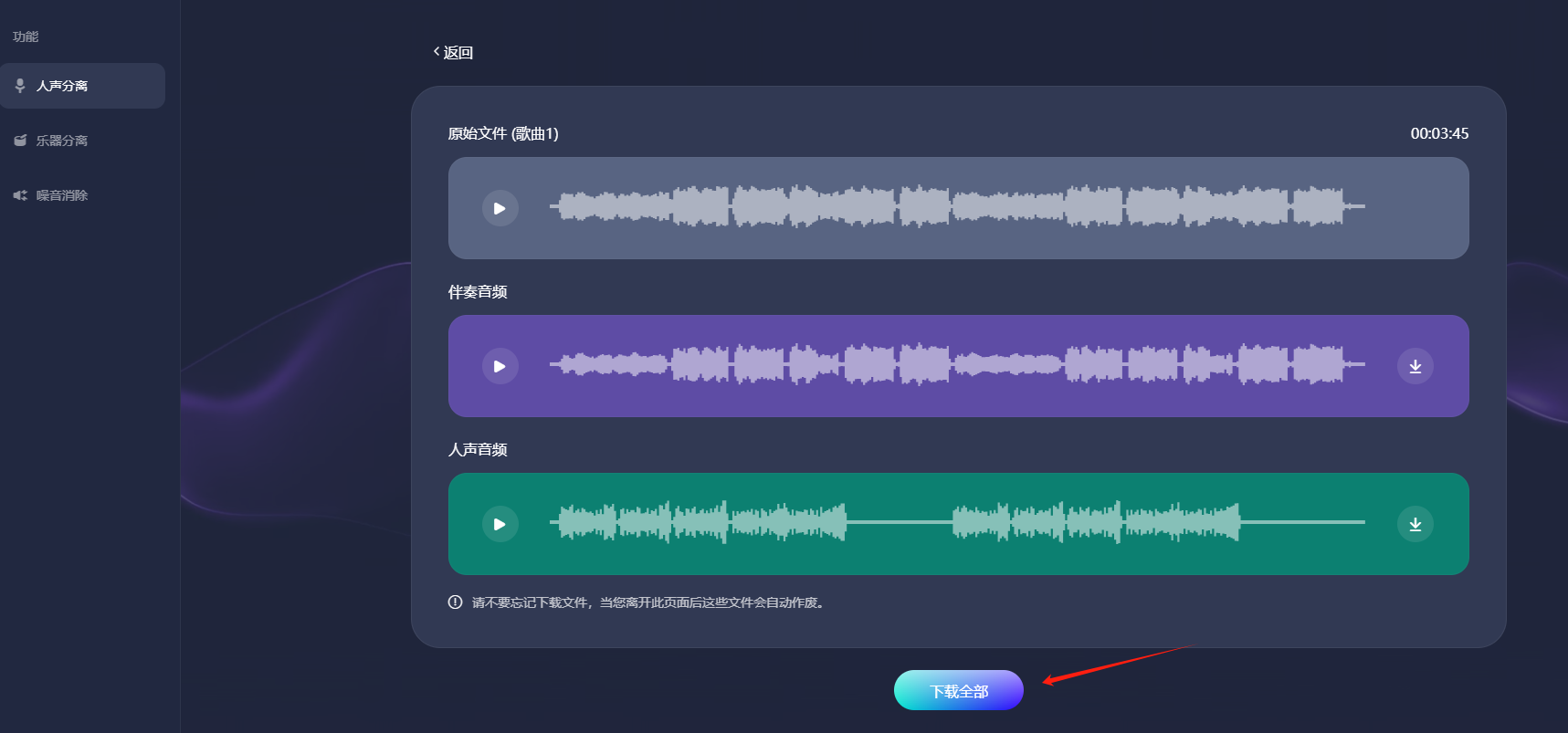
步骤3.AI处理完成后,会生成伴奏音频和人声音频,点击“下载全部”即可把音频下载到您的电脑上。
注意:请不要忘记下载文件,当您离开此页面后这些文件会自动作废。
三、基于声音传播特性的方法
理论上,可以根据声音的传播速度、传播介质等信息来分离人声和背景音乐。然而,在实际应用中,这种方法可能受到许多因素的影响,如环境噪声、多径传播等,因此分离效果可能并不理想。因此,这种方法通常需要结合其他方法一起使用,以获得更好的分离效果。
四、分离过程中的注意事项
音频质量:原始音频文件的质量对分离效果有很大影响。如果音频文件存在噪声或失真等问题,那么分离后的人声和背景音乐质量也会受到影响。
分离精度:虽然现有的分离技术已经取得了一定的成果,但要想实现完全准确的人声和背景音乐分离仍然是一个挑战。因此,在实际应用中需要根据具体需求进行权衡和调整。
后处理:分离出的人声和背景音乐可能需要进行后处理,如音量调整、音质修复等操作,以提高其音质和音量。
五、结论与展望
如何人声和背景音乐分离出来?以上是三种方法和注意事项的分享。随着音频处理技术的不断发展和人工智能技术的广泛应用,人声和背景音乐的分离技术将会越来越成熟和高效。

 从歌曲提取人声的简单教程,新手向
从歌曲提取人声的简单教程,新手向

 音乐伴奏提取的四个方法,速戳收藏了解
音乐伴奏提取的四个方法,速戳收藏了解
 如何提取音频里的人声?学会这一招,音频人声轻松提取
如何提取音频里的人声?学会这一招,音频人声轻松提取
 如何把歌曲去掉人声?自制伴奏:告别人声的简单步骤
如何把歌曲去掉人声?自制伴奏:告别人声的简单步骤
 音乐怎么去除人声?轻松去除人声,享受纯音乐体验
音乐怎么去除人声?轻松去除人声,享受纯音乐体验
 怎么把音乐中的人声去掉?音乐人声去除,简单又实用
怎么把音乐中的人声去掉?音乐人声去除,简单又实用
 用这个神器,伴奏音乐免费下载!
用这个神器,伴奏音乐免费下载!
 新手攻略:北京欢迎你伴奏制作提取的简便教程
人声背景音乐分离的技巧,还有注意事项
新手攻略:北京欢迎你伴奏制作提取的简便教程
人声背景音乐分离的技巧,还有注意事项
 免费背景音乐哪里找?这几个方法必看
视频如何提取背景音乐?一键提取,视频背景音乐不再难
如何提取音频中的纯人声?纯人声提取技巧,让你惊艳
免费背景音乐哪里找?这几个方法必看
视频如何提取背景音乐?一键提取,视频背景音乐不再难
如何提取音频中的纯人声?纯人声提取技巧,让你惊艳