




在音频处理领域,将音频中的人声和背景音乐分离是一项既复杂又富有挑战性的任务。然而,随着数字信号处理技术和人工智能算法的不断进步,这一任务变得日益可行。本文将从人声和音乐分离的基本原理出发,探讨几种常用的分离方法,并详细介绍其操作步骤和注意事项,旨在为音频处理爱好者和专业人士提供一份全面且实用的指南。
一、基本原理与前提条件
音频信号通常是由多个频率成分组成的复合信号,其中人声和背景音乐分别占据不同的频段。人声主要集中在中频区域,具有清晰的谐波结构和一定的动态范围,而背景音乐则可能覆盖更广泛的频段,包括低频的鼓点、中频的旋律和高频的乐器音色。这种频率分布的差异为人声和音乐的分离提供了理论基础。
要实现人声和音乐的分离,通常需要满足以下条件:
高质量的音频源:原始音频的质量直接影响分离效果。高质量的音频源能够提供更多细节,使得分离过程更加准确。
合适的分离工具:不同的分离工具和方法具有不同的优缺点。选择合适的工具和方法对于获得理想的分离效果至关重要。
充足的计算资源:一些先进的分离算法(如深度学习模型)需要大量的计算资源。确保你的计算机或服务器具有足够的内存、CPU和GPU资源,以支持高效的分离过程。
二、常用分离方法
频谱编辑法:一种基于频率特性的分离方法。通过专业的音频编辑软件可以观察到音频的频谱图。在这个图上,不同频率的成分以不同的颜色和高度显示。通过细致地调整各个频段的音量,可以逐渐减弱背景音乐,同时保留人声。这种方法需要一定的耐心和技巧,但效果往往非常显著。
中置声道提取法:在立体声音频中,人声通常位于左右声道的中央位置,即中置声道。通过提取中置声道的信息,可以得到相对纯净的人声。许多音频编辑软件都提供了中置声道提取的功能。使用这种方法时,需要注意调整提取的参数,以平衡人声的清晰度和背景音乐的残留程度。
机器学习算法:近年来,基于深度学习的音频分离技术取得了显著的进展。这些算法通过训练大量的音频数据模型,学习到了人声和背景音乐的特征。使用时,只需上传待分离的音频文件,算法会自动进行处理并输出分离后的人声和背景音乐。
三、操作步骤与注意事项
以易我人声分离为例,以下是使用机器学习算法进行人声和音乐分离的具体操作步骤:
第一步:进入易我人声分离的官网首页,点击“立即提取”,进入功能页面。

第二步:选择“人声分离”功能后,把原始歌曲文件上传到网页窗口中,然后等待AI自动识别处理,等待期间无需任何额外操作。

第三步:AI处理完成后,会从歌曲中提取出纯伴奏和纯人声,您可以分别试听。试听后若无任何问题,点击“下载全部”就能获得分离出的纯伴奏和纯人声了。
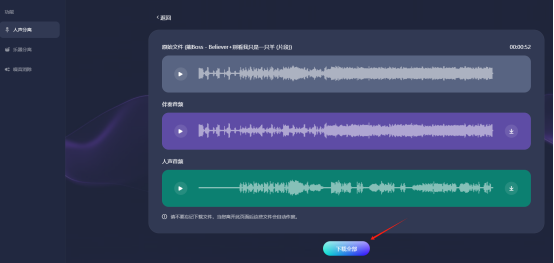
在使用任何分离方法时,都需要注意以下几点:
确保音频质量:高质量的音频源是获得理想分离效果的前提。
选择合适的分离工具:不同的工具和方法具有不同的优缺点。根据实际需求和个人技能水平选择合适的工具。
保存文件:确保保存分离后的人声和背景音乐文件以备后用。
四、结语
人声和音乐分离是一项复杂而富有挑战性的任务,但随着技术的不断进步,我们有更多的方法和工具可以选择,这些工具和方法为我们提供了前所未有的便利和可能性。

 一段音频如何去背景音乐,只留下人声?
一段音频如何去背景音乐,只留下人声?

 新手必看!分离人声网站的功能、特色和使用方法
新手必看!分离人声网站的功能、特色和使用方法
 在哪找小星星原版伴奏纯音乐歌曲?这些方法你一定不知道
如何从歌曲中提取伴奏?轻松提取歌曲伴奏
怎么去掉伴奏?伴奏去除小技巧分享
在哪找小星星原版伴奏纯音乐歌曲?这些方法你一定不知道
如何从歌曲中提取伴奏?轻松提取歌曲伴奏
怎么去掉伴奏?伴奏去除小技巧分享
 一首歌怎么去掉伴奏?成为音乐DIY达人
伴奏里的人声怎么消除?伴奏人声轻松去除
一首歌怎么去掉伴奏?成为音乐DIY达人
伴奏里的人声怎么消除?伴奏人声轻松去除
 如何去掉歌曲伴奏?简单实用的方法
如何去掉歌曲伴奏?简单实用的方法
 制作歌曲梁祝化蝶伴奏的教程,音乐爱好者必看
制作歌曲梁祝化蝶伴奏的教程,音乐爱好者必看
 这个工具让你轻松做到音频人声分离
这个工具让你轻松做到音频人声分离
 怎么从原曲中提取发如雪伴奏?
怎么从原曲中提取发如雪伴奏?
 视频怎么识别背景音乐并提取音乐?这些方法很好用
视频怎么识别背景音乐并提取音乐?这些方法很好用