




AI分离人声,简单来说就是利用人工智能算法把音频文件中的人声与其他声音(比如伴奏)分离开来,这样一来我们就可以得到清晰、干净的人声。本文将从AI分离人声的技术原理出发,为广大用户讲解AI工具和人声分离的具体步骤。
原理一:基于时间频域的方法
基于时间频域的方法是最早被提出和广泛应用的一种方法。其核心思想是通过观察音频信号在时间域和频域的特点来分离人声和背景音。常用的技术包括短时傅里叶变换(STFT)、相位重构、频谱减法等。
短时傅里叶变换(STFT):将音频信号分割成多个短时间段,并对每个时间段进行傅里叶变换,以获取音频信号在时间和频率上的分布特性。这有助于识别并分离人声和背景音。
相位重构:在分离出音频信号的不同成分后,需要通过相位重构技术来恢复原始音频信号的相位信息,以确保分离后的音频信号在听觉上保持连贯和一致。
频谱减法:通过分析音频信号的频谱特性,尝试从混合音频中减去背景音的频谱成分,从而得到相对纯净的人声或伴奏。
原理二:基于深度学习的方法
随着深度学习的发展,基于深度学习的人声分离方法也得到了广泛应用。这种方法利用神经网络模型对音频信号进行处理,通过训练模型学习人声和背景音之间的关系,从而实现人声分离。
神经网络模型:常用的深度学习模型有卷积神经网络(CNN)、循环神经网络(RNN)、深度神经网络(DNN)等。这些模型能够高效地处理复杂的音频信号,并实现对人声和背景音的精准分离。
训练过程:通过大量的标注数据(即已知人声和背景音分离结果的音频样本)来训练神经网络模型。在训练过程中,模型会学习如何识别并分离音频信号中的人声和背景音成分。
分离过程:在模型训练完成后,可以将待处理的音频信号输入到模型中,模型会根据学习到的知识来分离出音频信号中的人声和背景音。
AI分离人声技术原理的应用
目前,基于AI的人声分离技术已经被广泛应用于音乐制作、后期制作、音频分析、版权保护等多个领域。目前市面上也涌现了一些优秀的人声分离工具,易我人声分离正是一款备受好评的AI工具。
易我人声分离的特色功能是人声分离、乐器分离和噪音消除,它依靠人工智能算法,能够从音乐和视频中,快速分离人声与伴奏,还能分离出低音、钢琴音、鼓声等特定的乐器声音。
以用户最关注的“人声分离”为例,我们来看看易我人声分离的具体操作步骤:
步骤1.访问并登录易我人声分离官网页面,选择“人声分离”功能。
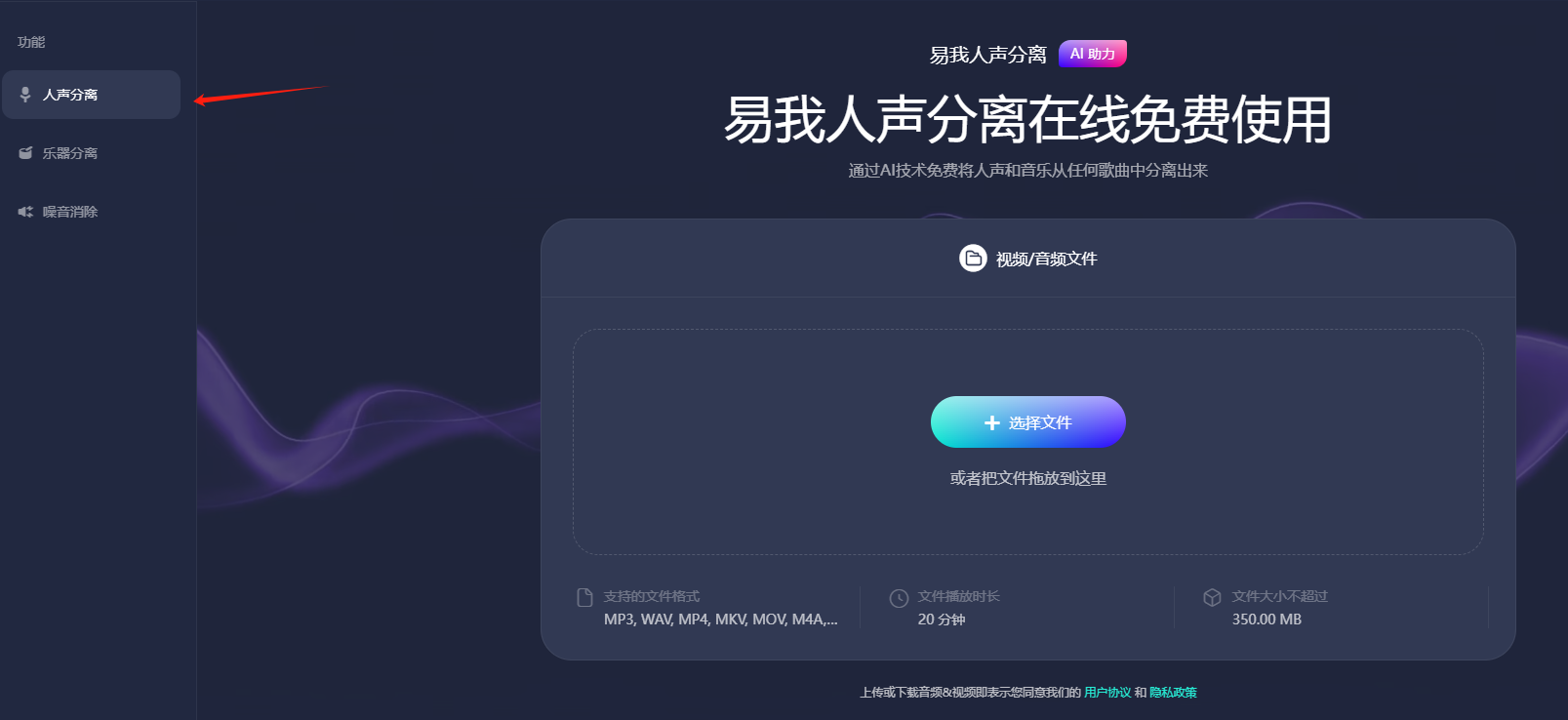
步骤2.点击“选择文件”,把音频或者视频文件上传到网页窗口中(或者直接拖拽文件到窗口中),等待AI处理。


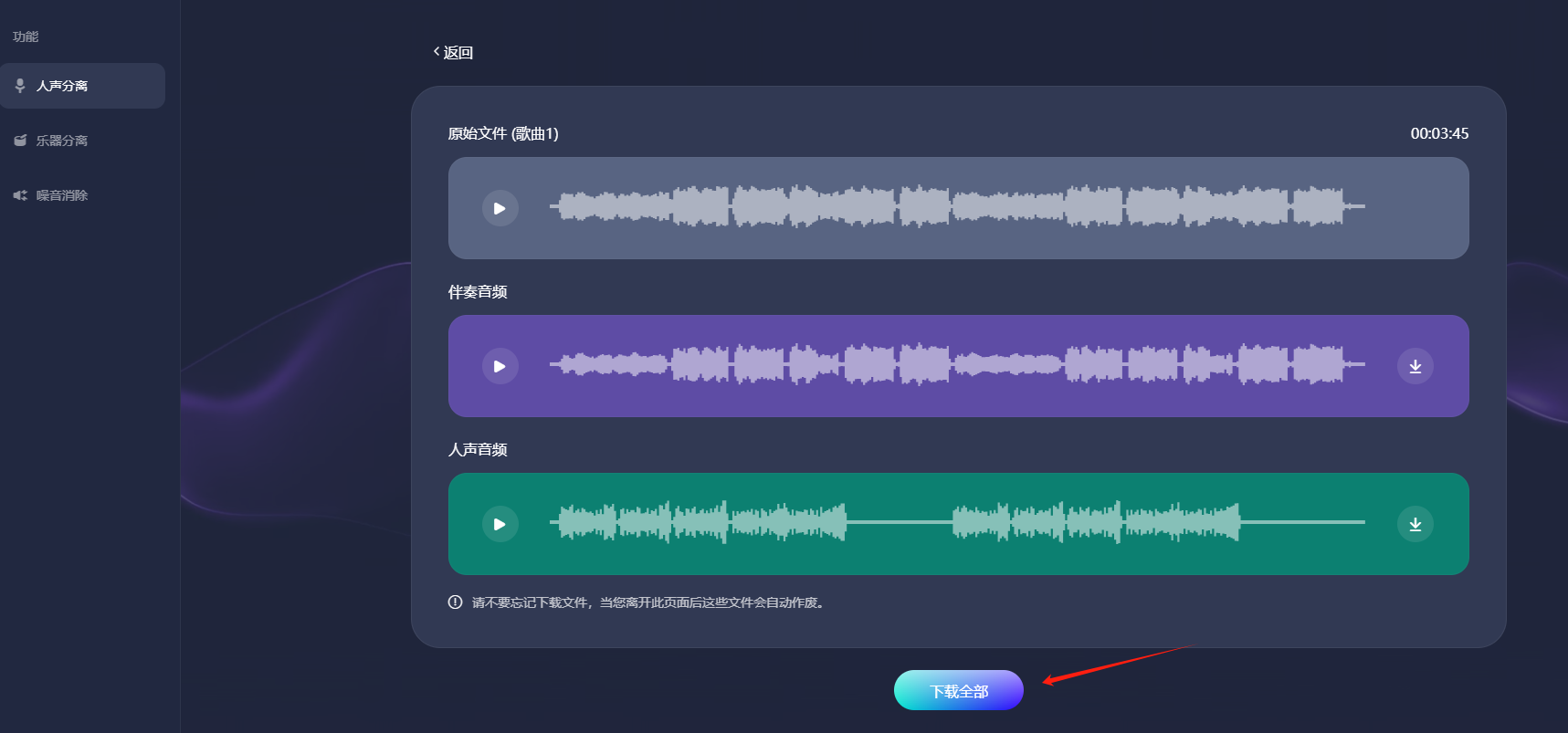
步骤3.AI处理完成后,会生成伴奏音频和人声音频,点击“下载全部”即可把音频下载到您的电脑上。
注意:请不要忘记下载文件,当您离开此页面后这些文件会自动作废。
AI技术的未来挑战
尽管AI分离人声的技术已经取得了显著的进展,但仍面临一些挑战。例如,对于复杂多变的音乐场景和音频信号,模型的分离效果可能会受到影响。因此,未来的研究需要进一步优化算法模型、提高分离效果,并探索更多的应用场景和可能性。
结语
综上所述,AI分离人声的技术原理主要基于时间频域的方法和深度学习的方法。这两种方法各有优劣,在实际应用中需要根据具体需求和场景进行选择和优化。

 歌曲小白杨伴奏的提取步骤讲解
歌曲小白杨伴奏的提取步骤讲解

 怎么提取BY2的经典代表作——爱丫爱丫伴奏?
怎么提取BY2的经典代表作——爱丫爱丫伴奏?
 怎样把视频转成音频?三种简单易行的方法
怎样把视频转成音频?三种简单易行的方法
 音频除噪攻略:从录制到后期去噪的技巧
音频除噪攻略:从录制到后期去噪的技巧
 怎么分离视频中的音频?五个音频分离方法
怎么分离视频中的音频?五个音频分离方法
 音频分离人声和音乐免费工具和教程示例
音频分离人声和音乐免费工具和教程示例
 免费的视频提取音乐网站,错过后悔!
免费的视频提取音乐网站,错过后悔!
 从哪里下载东方红伴奏原版?这个方法不费力!
从哪里下载东方红伴奏原版?这个方法不费力!
 只要三步,实现人声与背景音乐分离
只要三步,实现人声与背景音乐分离
 录音嘈杂怎么提取人的声音?降噪和凸显人声的技巧
录音嘈杂怎么提取人的声音?降噪和凸显人声的技巧
 伴奏提取教程:如何提取爱的华尔兹伴奏
伴奏提取教程:如何提取爱的华尔兹伴奏
 坐上火车去拉萨伴奏的下载和提取方法
坐上火车去拉萨伴奏的下载和提取方法