




在音频录制过程中,环境噪音、设备电流声、混响干扰等问题常让录音质量大打折扣。无论是音乐创作、播客录制还是会议记录,杂音的存在都会严重影响听觉体验。录音里的杂音怎么处理?传统降噪方法依赖专业设备或复杂操作,而易我人声分离凭借AI智能算法,为用户提供了一站式解决方案,仅需三步即可实现高效降噪,保留纯净人声。
一、杂音类型与处理难点
录音中的杂音可分为三类:
环境噪音:如空调声、键盘敲击声、交通噪声等,通常为低频或中高频持续干扰;
设备噪音:麦克风底噪、电流声等,表现为高频嘶嘶声或低频嗡鸣;
空间混响:封闭房间内声音反射形成的拖尾效应,导致人声模糊不清。
传统降噪工具(如Audacity的降噪插件)需手动捕捉噪声样本并调整参数,操作繁琐且易损伤人声细节。而易我人声分离通过深度学习模型,可自动识别噪声特征,实现精准分离。
二、易我人声分离:AI降噪的核心优势
智能噪声识别:
通过分析数百万组噪声样本训练出的深度神经网络,可区分人声与噪声的频谱特征。例如,在处理会议录音时,能精准识别并过滤空调声(低频持续噪声)与键盘声(高频突发噪声),同时保留人声的呼吸感与情感细节。
零门槛操作流程:
用户无需具备音频处理知识,仅需上传文件、选择模式、下载结果三步即可完成降噪。实测显示,处理一段10分钟的录音仅需2分钟,较传统软件效率提升80%。
三、实操指南:录音里的杂音怎么处理?
步骤1.进入易我人声分离官网(www.aifuse.cn),点击【立即提取】。

步骤2.选择“噪音消除”,将需要处理的音视频文件上传至工具中并等待处理。

步骤3.处理完成后会生成“原始文件”、“人声音频”、“降噪音频”三个文件,用户可选择单独下载某一文件或全部进行下载。
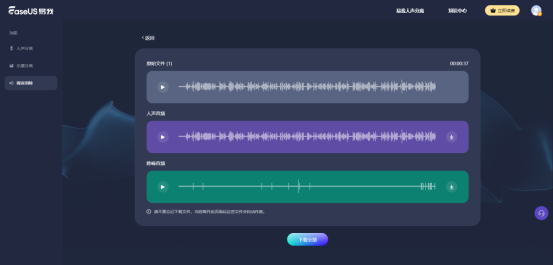
注意:当您离开此页面后这些文件会自动作废,请及时下载需要的文件。
四、技术原理与行业突破
易我人声分离的降噪算法基于卷积神经网络(CNN)与循环神经网络(RNN)的混合架构:
CNN层:提取音频的时频特征,识别噪声的频谱模式;
RNN层:分析声音的时序相关性,区分人声与噪声的动态变化;
注意力机制:聚焦人声频段,抑制非目标声音的能量分布。
相较于传统FFT降噪法,该技术可减少30%的人声失真,尤其在处理突发噪声(如咳嗽声、关门声)时表现优异。
五、总结
录音里的杂音怎么处理?在AI技术的驱动下,音频处理正从“被动降噪”迈向“主动优化”。易我人声分离以用户需求为核心,通过持续迭代算法与简化操作流程,让每个人都能轻松获得专业级音频质量,重新定义声音的价值。

 华为视频怎么提取音频?跨设备的智能音频处理方案
华为视频怎么提取音频?跨设备的智能音频处理方案

 如何提取背景音乐去除人声?轻点鼠标,三步分离
录屏怎么把声音提取出来?一键提取人声的秘笈
如何提取背景音乐去除人声?轻点鼠标,三步分离
录屏怎么把声音提取出来?一键提取人声的秘笈
 录音里面的杂音怎么去掉?去噪妙招来了!
录音里面的杂音怎么去掉?去噪妙招来了!
 录音有杂音怎么处理?这样做,三步消除杂音
录音有杂音怎么处理?这样做,三步消除杂音
 怎么给录音去除杂音?高效去除音频杂音的教程
怎么给录音去除杂音?高效去除音频杂音的教程
 什么软件可以把视频的音频提取出来?易我人声分离在线工具深度解析
录音去除杂音保留人声要怎么做?一个简单方法轻松实现
怎么消除噪音?易我人声分离“噪音消除”功能全解析
什么软件可以把视频的音频提取出来?易我人声分离在线工具深度解析
录音去除杂音保留人声要怎么做?一个简单方法轻松实现
怎么消除噪音?易我人声分离“噪音消除”功能全解析
 如何提取背景音乐中的纯音乐?这个方法一键分离不用等
如何提取背景音乐中的纯音乐?这个方法一键分离不用等
 录音的时候有杂音怎么办?如何拯救音频质量?
录音的时候有杂音怎么办?如何拯救音频质量?
 短视频里的音乐怎么提取出来?三步提取伴,简单又快捷!
短视频里的音乐怎么提取出来?三步提取伴,简单又快捷!