




在数字音频处理领域,将人声与背景音乐分离是一个常见需求,尤其对于音乐制作、后期混音、卡拉OK制作等场景而言。尽管这一任务颇具挑战性,但借助现代技术和工具,我们仍然能够实现相对满意的分离效果。
那么,我们怎么把人声和音乐分离呢?本文将重点介绍两种常用的人声和音乐分离方法:基于频谱分析的音频编辑方法和基于深度学习的音频分离技术。
一、基于频谱分析的音频编辑方法
频谱分析是音频处理中的一项基础技术,它允许我们查看和编辑音频信号在不同频率上的分布。通过专业的音频编辑软件,如Adobe Audition、Audacity等,我们可以利用频谱分析工具来尝试分离人声和音乐。
首先,导入需要处理的音频文件,并在软件中打开频谱视图。通过观察频谱图,我们可以发现人声和音乐在频率分布上往往有所不同。人声通常集中在中频区域,而音乐则可能覆盖更广泛的频率范围。
接下来,我们可以使用均衡器或滤波器来调整不同频率段的音量。通过降低音乐所在频率段的音量,同时保持或增强人声所在频率段的音量,可以初步实现人声和音乐的分离。然而,这种方法需要一定的音频处理经验和技巧,并且对于复杂或混合程度较高的音频可能效果有限。
二、基于深度学习的音频分离技术
近年来,深度学习在音频处理领域取得了显著的突破,特别是在音频分离任务上。基于深度学习的音频分离技术通过训练大量的音频数据来学习如何区分和分离不同的声音源。
这里小编就给大家分享一款好用的在线AI音频编辑工具,它叫做易我人声分离。通过先进的音频处理技术,易我人声分离能够轻松应对各种音质和音量的音频文件,无论是清晰的录音还是嘈杂的现场环境,都能确保高质量的人声分离效果。
步骤1.访问并登录易我人声分离官网页面,选择“人声分离”功能。
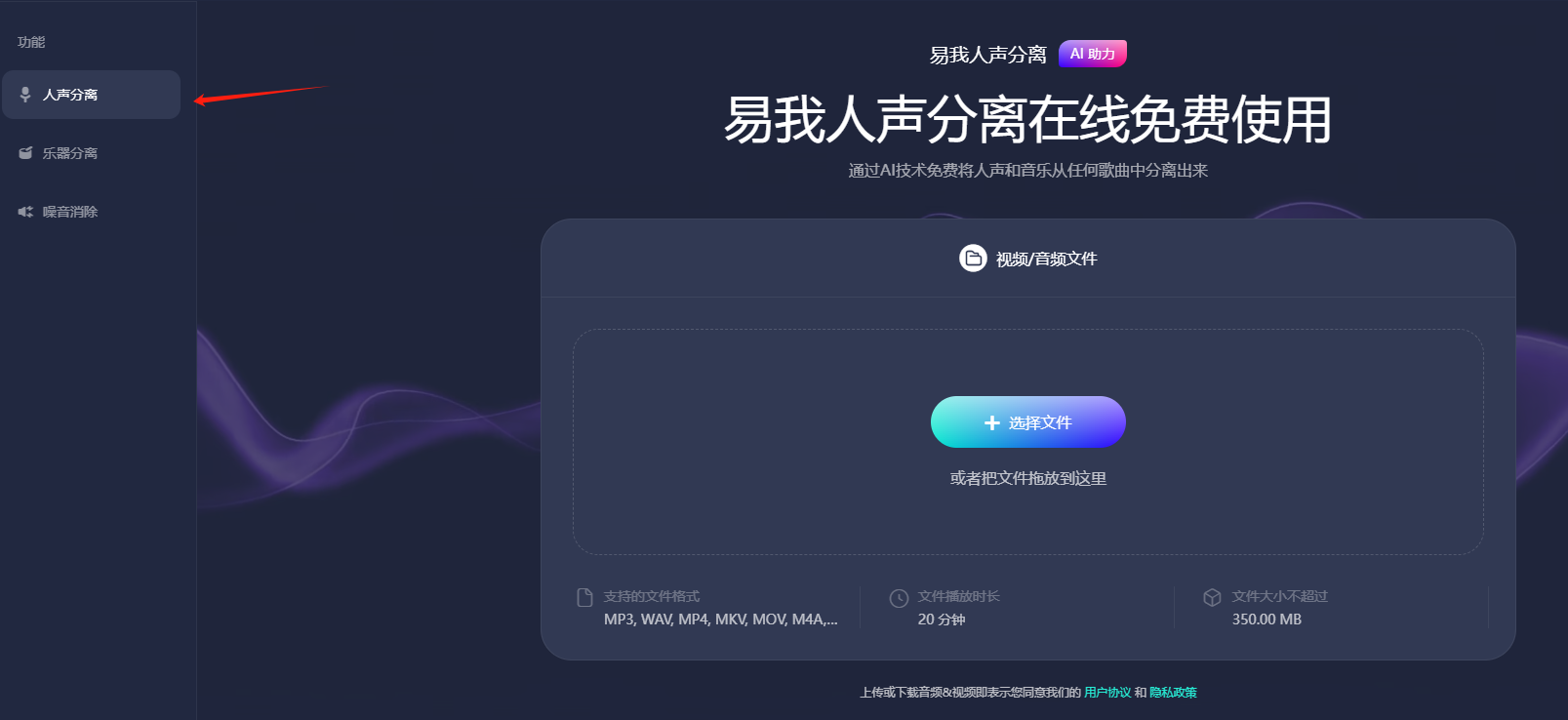
步骤2.点击“选择文件”,把音频或者视频文件上传到网页窗口中(或者直接拖拽文件到窗口中),等待AI处理。


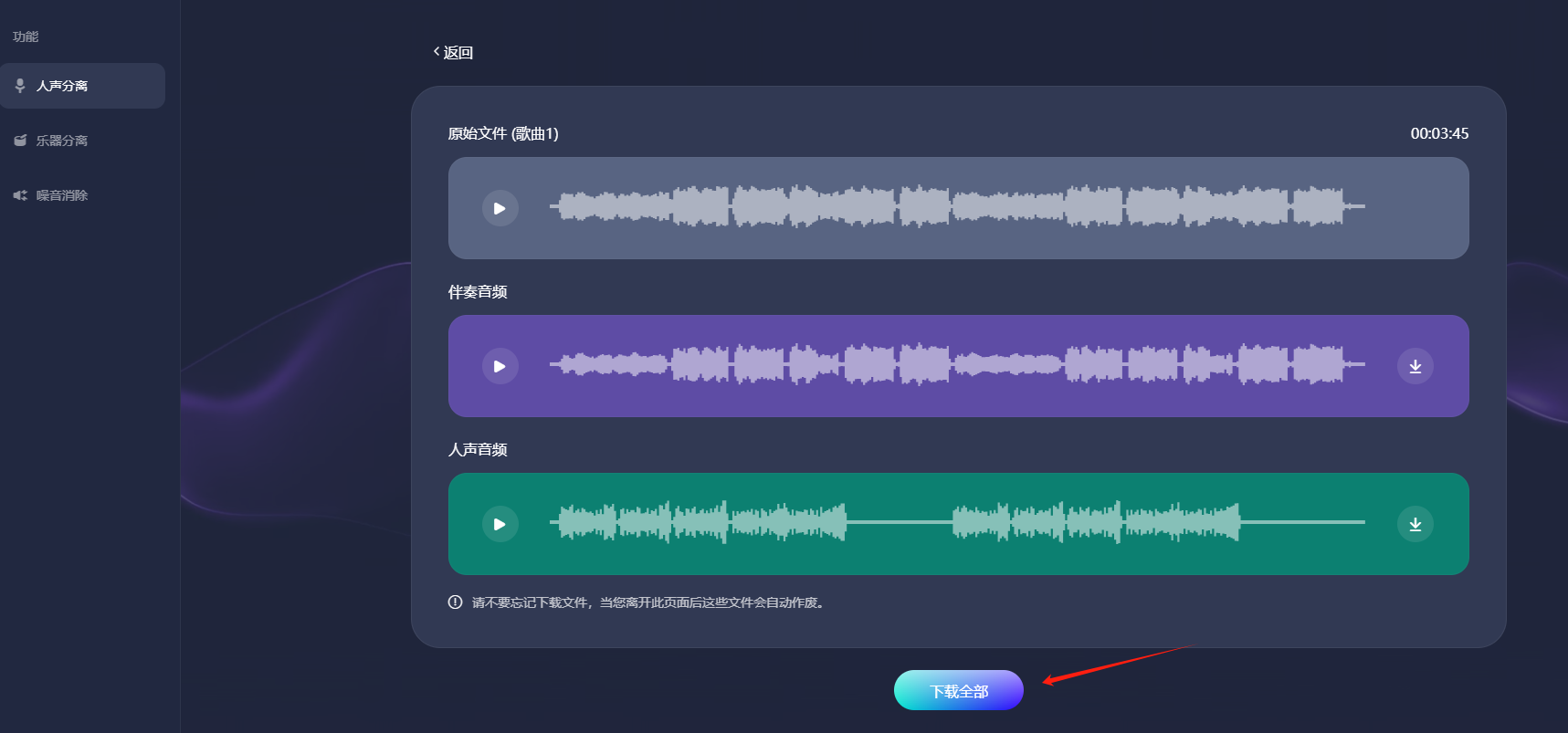
步骤3.AI处理完成后,会生成伴奏音频和人声音频,点击“下载全部”即可把音频下载到您的电脑上。
注意:请不要忘记下载文件,当您离开此页面后这些文件会自动作废。
然而,值得注意的是,基于深度学习的音频分离技术虽然强大,但也可能受到训练数据和模型复杂度的限制。在某些特定情况下,如音频质量较差、人声与音乐高度混合等,分离效果可能仍会受到影响。
三、总结
怎么把人声和音乐分离,以上就是全部分享了。总的来说,无论是基于频谱分析的音频编辑方法还是基于深度学习的音频分离技术,都有其独特的优势和局限性。在实际应用中,我们可以根据具体需求和条件选择合适的方法来实现人声和音乐的分离。
随着技术的不断进步和创新,我们期待未来能有更多高效、智能的音频分离方法出现,为音频处理领域带来更多的可能性。

 对一首歌曲,怎么去人声保留背景音乐?
对一首歌曲,怎么去人声保留背景音乐?

 这个在线免费的声音提取软件,简直太好用啦!
这个在线免费的声音提取软件,简直太好用啦!
 如何提取歌曲伴奏?轻松获取伴奏的实用方法
如何提取歌曲伴奏?轻松获取伴奏的实用方法
 怎么把音乐和人声分离?学会这一招,视频无声处理不再难
人声分离器免费版,音频处理神器!
怎么把音乐和人声分离?学会这一招,视频无声处理不再难
人声分离器免费版,音频处理神器!
 音频分离人声和音乐,只需轻点鼠标就能办到!
音频分离人声和音乐,只需轻点鼠标就能办到!
 专门下伴奏的软件有哪些?怎么制作伴奏?
专门下伴奏的软件有哪些?怎么制作伴奏?
 在线AI人声分离工具,动动鼠标即可分离人声和音乐!
伴奏怎么制作?从歌曲中如何制作出纯伴奏?
在线AI人声分离工具,动动鼠标即可分离人声和音乐!
伴奏怎么制作?从歌曲中如何制作出纯伴奏?
 歌曲怎么提取伴奏?学会这招,伴奏轻松提取!
歌曲怎么提取伴奏?学会这招,伴奏轻松提取!
 音乐如何去掉人声?音乐爱好者必看:去人声窍门分享
音乐如何去掉人声?音乐爱好者必看:去人声窍门分享
 如何提取背景音乐?背景音乐一键去除
如何提取背景音乐?背景音乐一键去除