




在数字音频技术日新月异的今天,人声分离技术作为一项前沿的应用,正逐步改变着我们对音频编辑与后期处理的理解。人声分离提取人声技术能够从复杂的音乐或影视声音中精准地提取出人声,为音乐制作、影视后期、教育、语音识别等多个领域带来了前所未有的便利与创新。
一、人声分离技术的奥秘
人声分离,简而言之,是指从包含多种声音元素的音频信号中,单独提取出人声部分的过程。这一过程并非简单地将音量调大或调小,而是依赖于先进的信号处理算法和机器学习技术。这些技术能够分析音频的频谱特征、时间结构以及和声特性,从而智能地区分人声与其他声音(如背景音乐、环境音效等)。
核心在于,人声具有独特的频谱范围和动态特性,如特定的基频和谐波结构。通过训练大量的音频数据,算法能够学习到这些特征,并据此实现精准的分离。此外,深度学习技术的引入,尤其是卷积神经网络(CNN)和循环神经网络(RNN)的应用,极大地提高了人声分离的准确性和效率。
二、人声分离技术的在线工具
易我人声分离这个在线就能直接使用的AI工具,能帮助我们对音频和视频文件进行人声分离提取人声。该工具不需要下载安装,在网页上就能使用,详细的操作步骤如下:
步骤1.访问并登录易我人声分离官网页面,选择“人声分离”功能。
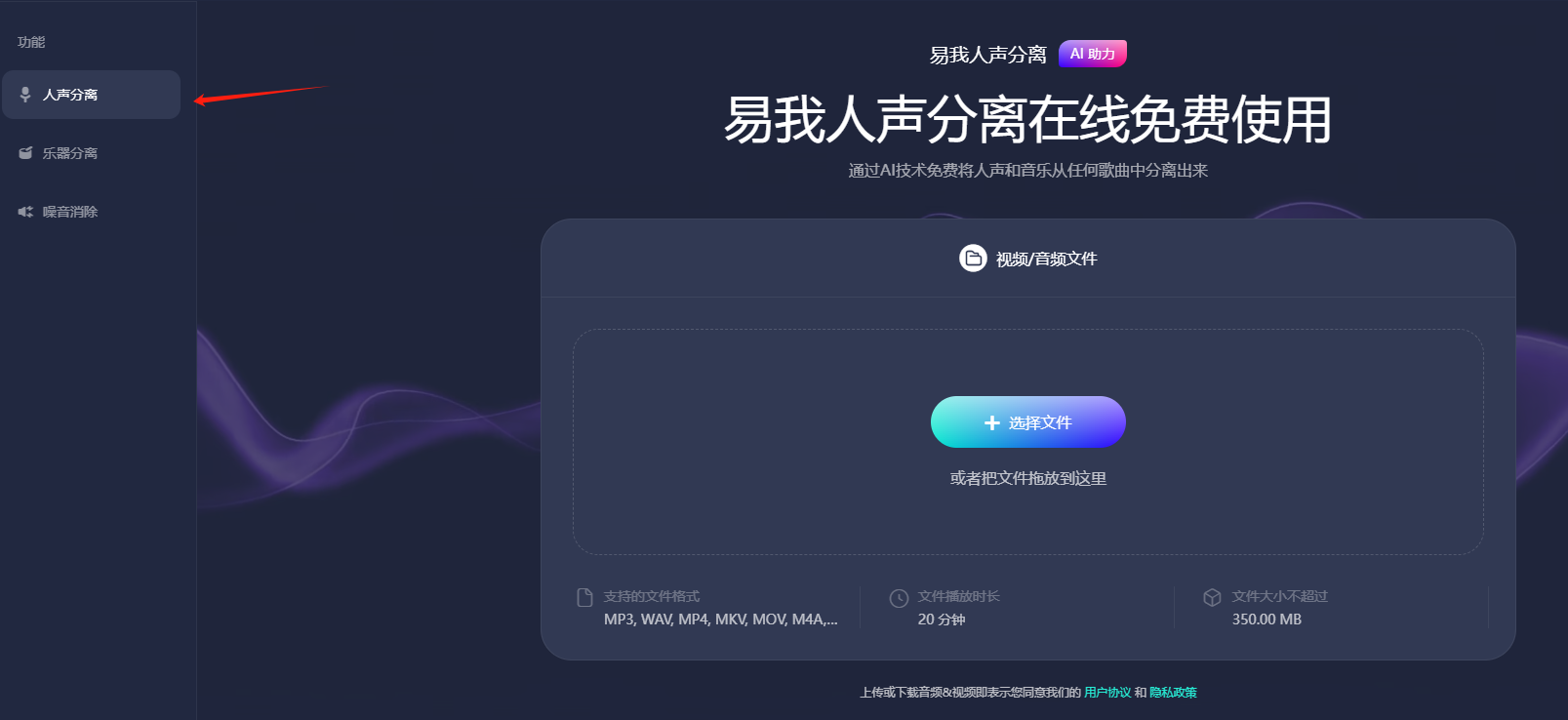
步骤2.点击“选择文件”,把音频或者视频文件上传到网页窗口中(或者直接拖拽文件到窗口中),等待AI处理。


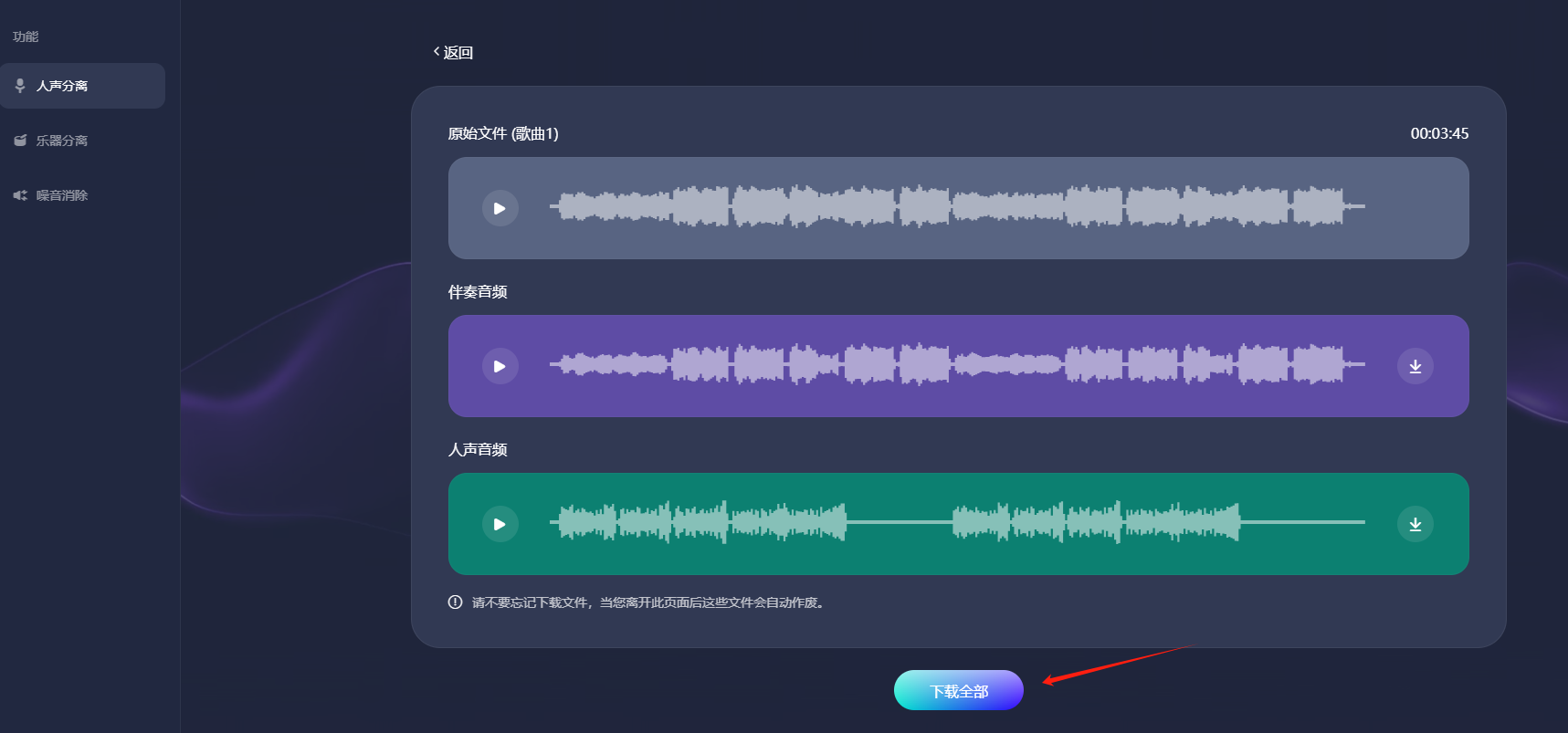
步骤3.AI处理完成后,会生成伴奏音频和人声音频,点击“下载全部”即可把音频下载到您的电脑上。
注意:请不要忘记下载文件,当您离开此页面后这些文件会自动作废。
三、人声分离技术的应用领域
音乐制作与混音:对于音乐制作人而言,人声分离技术允许他们在不改变原有伴奏的情况下,对人声进行独立的编辑、修音或效果处理,极大地提升了创作的灵活性和自由度。
影视后期制作:在影视作品中,清晰的人声对于对话理解和情感传达至关重要。人声分离技术可以帮助后期制作人员优化对话清晰度,减少背景噪音干扰,提升观影体验。
教育与无障碍辅助:在教育领域,该技术可用于制作无障碍学习资源,如为听力障碍者提供仅含人声的音频版本,或帮助语言学习者专注于语音练习。
语音识别与增强:在智能语音助手、会议记录等应用场景中,人声分离能有效提升语音识别的准确率,尤其是在嘈杂环境中,通过分离人声,可以显著提高语音信号的清晰度。
总结
总之,人声分离提取人声的技术作为音频处理领域的一项革命性突破,正以其独特的魅力,引领着音频创作与应用的全新潮流。随着技术的不断成熟和完善,我们有理由相信,这一技术将在更多领域绽放光彩,为我们的生活和工作带来更多便利与惊喜。

 去除背景音乐的软件,让音频编辑更得心应手
去除背景音乐的软件,让音频编辑更得心应手
 怎么提取音乐里的伴奏? 提取伴奏的2个实用技巧
怎么提取音乐里的伴奏? 提取伴奏的2个实用技巧
 音频怎么提取人声?人声提取技巧
音频怎么提取人声?人声提取技巧
 如何去除背景音乐?去除背景音乐技巧
如何去除背景音乐?去除背景音乐技巧
 如何分离视频中的人声和背景音乐?人声分离方法介绍
如何分离视频中的人声和背景音乐?人声分离方法介绍
 声音分离软件:更便捷的音频编辑方式
声音分离软件:更便捷的音频编辑方式
 如何在线提取视频音乐?易我人声分离的应用实践
如何在线提取视频音乐?易我人声分离的应用实践
 视频去背景音乐的多种方法,视频编辑者的福音
视频去背景音乐的多种方法,视频编辑者的福音
 背景音乐提取的诀窍!让你轻松留下纯音乐
背景音乐提取的诀窍!让你轻松留下纯音乐
 去原唱保留伴奏软件:音乐编辑的新选择
去原唱保留伴奏软件:音乐编辑的新选择
 歌曲去人声怎样才能实现?技巧汇总,一文看懂
歌曲去人声怎样才能实现?技巧汇总,一文看懂
 提取背景音乐的软件:让美妙旋律触手可及
提取背景音乐的软件:让美妙旋律触手可及