




近年来,随着人工智能(AI)技术的迅猛发展,AI在音频处理领域的应用日益广泛,其中AI提取人声技术更是为音乐制作、语音识别、卡拉OK制作等多个领域带来了革命性的变革。
一、音频的基本构成与提取人声的目标
音频通常由多个声音源混合而成,包括人声、乐器声、环境音等。在提取人声时,我们的目标是增强人声的信号,同时减弱或消除其他声音。这要求我们能够精确地区分并分离出音频中的人声成分,同时保持其原有的音质和清晰度。
二、AI提取人声的技术原理

AI提取人声技术主要基于深度神经网络模型,通过训练大量标注好的数据,模型能够学习到人声与音乐之间的细微差异,从而实现高精度分离。这一技术原理大致可以分为以下几个步骤:
模型训练:利用包含人声信号和背景噪声的混合音频数据,对深度学习模型进行训练。通过不断调整模型的参数,使其能够准确分离出人声信号和背景噪声。
特征提取:在模型训练过程中,深度学习模型会自动提取音频信号中的特征,这些特征可以是人声信号的频谱特征、时域特征等。这些特征为后续的分离处理提供了关键信息。
分离处理:根据提取的特征,深度学习模型对混合音频信号进行分离处理,得到分离后的人声信号和背景噪声信号。这一步骤是AI提取人声技术的核心所在,其分离效果直接影响到最终的人声质量。
三、AI提取人声的实现方法
目前,AI提取人声的实现方法主要有两种:基于专业音频编辑软件的方法和基于在线AI音频处理工具的方法。
对于专业的音频处理需求,使用专业的音频编辑软件是不错的选择。通过这些软件,用户可以精确地选取人声频段,使用降噪、均衡器等工具来减弱背景音乐,从而提取出清晰的人声。不过这种方法需要用户具备一定的音频处理知识,但能够实现较高的人声提取质量。
对于没有安装专业音频编辑软件或只是偶尔需要处理音频的用户来说,在线AI音频处理工具可能更适合。这些工具无需安装,直接在网页上操作,简单易用。例如,易我人声分离这款在线AI音频处理工具就提供了人声提取的功能。用户只需上传音频文件,选择相应的处理选项,稍等片刻即可下载提取后的人声音频。
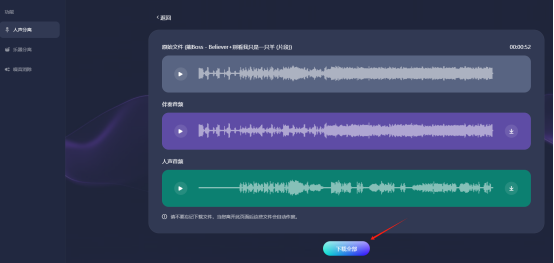
第一步:进入易我人声分离的官网首页,点击“立即提取”,进入功能页面。

第二步:选择“人声分离”功能后,把原始歌曲文件上传到网页窗口中,然后等待AI自动识别处理,等待期间无需任何额外操作。

第三步:AI处理完成后,会从歌曲中提取出纯伴奏和纯人声,您可以分别试听。试听后若无任何问题,点击“下载全部”就能获得分离出的纯伴奏和纯人声了。
四、AI提取人声技术的优势与应用
操作简便:用户只需通过相关软件或应用上传歌曲文件,选择去人声功能,便可轻松获得纯净的伴奏音频。这种一键式的操作方式大大降低了使用门槛。
分离效果出色:借助先进的深度学习算法,AI能够精确地识别和分离音频中的人声和伴奏,确保分离后的音质清晰、层次分明。
适用范围广泛:AI提取人声技术不仅适用于流行歌曲,还可应用于民谣、摇滚、古典等多种音乐风格。无论是想要翻唱热门单曲还是演绎经典老歌,AI都能提供优质的伴奏支持。
五、总结与展望
AI提取人声技术的出现为音乐制作、语音识别等领域带来了前所未有的便利。它降低了使用门槛,提升了处理效率,丰富了音乐创作的手段。随着AI技术的不断发展和完善,我们有理由相信,AI提取人声技术将在未来音乐领域发挥更加重要的作用。

 伴奏提取器免费分享,还有教程,小白千万别错过
伴奏提取器免费分享,还有教程,小白千万别错过

 爱拼才会赢伴奏原版怎么获取?内附免费提取歌曲伴奏的教程
爱拼才会赢伴奏原版怎么获取?内附免费提取歌曲伴奏的教程
 全方位攻略:音乐人声分离的工具与技巧汇总
怎么提取《少年壮志不言愁》伴奏?
全方位攻略:音乐人声分离的工具与技巧汇总
怎么提取《少年壮志不言愁》伴奏?
 怎么把人声和背景声分离?分离人声的技巧
怎么把人声和背景声分离?分离人声的技巧
 怎么分离背景音乐和人声?分离人声与背景音窍门
怎么分离背景音乐和人声?分离人声与背景音窍门
 如何把人声和背景音乐分离?学会这招,轻松分离人声和音乐!
如何把人声和背景音乐分离?学会这招,轻松分离人声和音乐!
 如何在线去人声留伴奏?一键去人声,伴奏制作一步到位
如何在线去人声留伴奏?一键去人声,伴奏制作一步到位
 自制高耀太火花伴奏!轻松制作纯伴奏音乐
自制高耀太火花伴奏!轻松制作纯伴奏音乐
 免费伴奏提取网站,易我人声分离使用教程
免费伴奏提取网站,易我人声分离使用教程
 我和我的祖国歌曲伴奏如何免费提取?
我和我的祖国歌曲伴奏如何免费提取?
 视频怎么去背景音乐只要人声?方法解析
视频怎么去背景音乐只要人声?方法解析