




在音频处理领域,将音频人声背景音乐分离是一项具有挑战性的任务。然而,随着音频处理技术的不断进步,特别是人工智能(AI)技术的快速发展,这一任务已经变得越来越容易实现。
一、技术原理
音频人声与背景音乐分离的技术原理主要基于信号处理、频谱分析和机器学习等理论。
信号处理:音频信号是一种复杂的波形,包含多种频率成分。人声通常位于中频区域,而背景音乐则可能覆盖更广泛的频率范围。通过信号处理技术,如滤波、降噪等,可以初步分离出人声和背景音乐。
频谱分析:频谱分析是音频处理中的一种重要方法,它可以将音频信号转换为频谱图,从而直观地观察不同频率成分的能量分布。在频谱图上,人声和背景音乐的频率分布通常有明显的差异,这为分离提供了依据。
机器学习:近年来,基于深度学习的音频分离技术取得了显著进展。通过训练模型学习人声与背景音乐之间的差异,可以实现对混合音频的精准分离。这种方法不仅效率高,而且能够处理复杂多变的音乐风格,保持原音频的自然度和清晰度。
二、音频人声背景音乐分离方法
目前,音频人声与背景音乐分离的方法主要分为传统方法和基于AI的方法两大类。
在传统方法中,有相位反转与消减和频谱编辑的方法。基于AI的方法主要是通过训练深度学习模型,如卷积神经网络(CNN)、循环神经网络(RNN)等,可以实现对音频信号的自动分离。这些模型能够学习到人声与背景音乐之间的细微差异,并在分离过程中保持音频的自然度和清晰度。
一些在线平台或软件,如易我人声分离,利用先进的机器学习算法,能够自动识别并分离音频中的人声和背景音乐。用户只需上传音频文件,选择分离模式,稍等片刻即可得到分离后的人声和音乐文件。这种方法操作简单,适合不具备专业音频处理知识的用户。
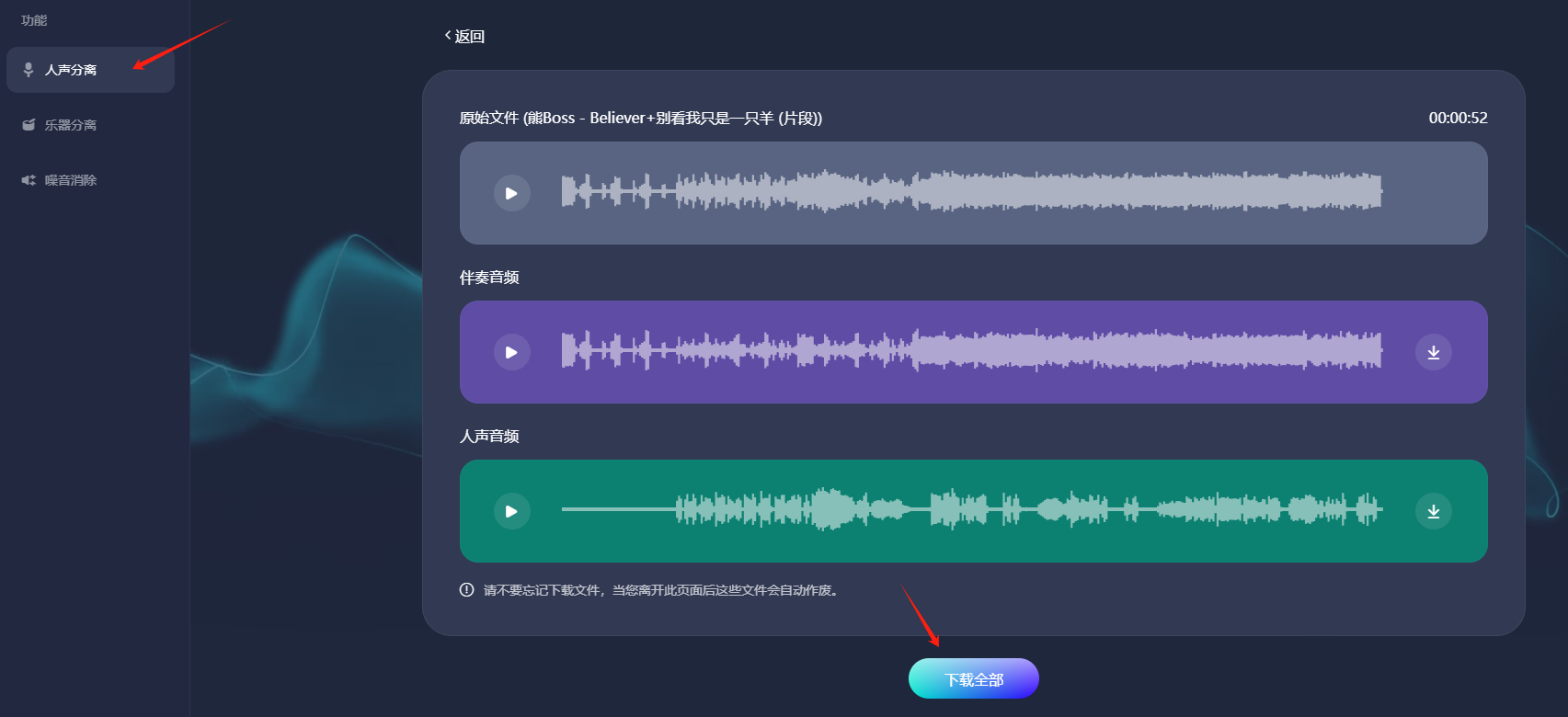
三、注意事项与挑战
选择合适的分离方法:根据实际需求和个人技能水平选择合适的分离方法。对于初学者,推荐使用基于AI的在线平台或软件;对于专业人士,可以选择专业音频处理软件或采用更复杂的信号处理方法。
保证音频质量:在进行分离操作前,确保音频文件的质量较高,以减少分离过程中的误差和失真。
预览与调整:在分离完成后,务必预览分离结果,并根据需要进行微调,以达到最佳的分离效果。
版权意识:在去除人声或背景音乐的过程中,要尊重原作者的版权,避免未经授权的修改和使用。
四、结论
音频人声背景音乐分离技术是一项具有广泛应用前景的技术。通过深入了解其技术原理、方法和应用,我们可以更好地利用这项技术为音乐制作、语音识别、视频制作等领域提供便利和支持。

 AI提取人声怎样实现?提取清晰人声其实很简单
AI提取人声怎样实现?提取清晰人声其实很简单

 伴奏提取器免费分享,还有教程,小白千万别错过
伴奏提取器免费分享,还有教程,小白千万别错过
 爱拼才会赢伴奏原版怎么获取?内附免费提取歌曲伴奏的教程
爱拼才会赢伴奏原版怎么获取?内附免费提取歌曲伴奏的教程
 全方位攻略:音乐人声分离的工具与技巧汇总
怎么提取《少年壮志不言愁》伴奏?
全方位攻略:音乐人声分离的工具与技巧汇总
怎么提取《少年壮志不言愁》伴奏?
 怎么把人声和背景声分离?分离人声的技巧
怎么把人声和背景声分离?分离人声的技巧
 怎么分离背景音乐和人声?分离人声与背景音窍门
怎么分离背景音乐和人声?分离人声与背景音窍门
 如何把人声和背景音乐分离?学会这招,轻松分离人声和音乐!
如何把人声和背景音乐分离?学会这招,轻松分离人声和音乐!
 如何在线去人声留伴奏?一键去人声,伴奏制作一步到位
如何在线去人声留伴奏?一键去人声,伴奏制作一步到位
 自制高耀太火花伴奏!轻松制作纯伴奏音乐
免费伴奏提取网站,易我人声分离使用教程
自制高耀太火花伴奏!轻松制作纯伴奏音乐
免费伴奏提取网站,易我人声分离使用教程
 我和我的祖国歌曲伴奏如何免费提取?
我和我的祖国歌曲伴奏如何免费提取?